
2.前置知识准备
学习爬虫的前置知识一、前言在学习爬虫之前,需要我们了解一些前置的知识,包括常用术语,开发流程,抓包工具,前端标签等。
学习爬虫的前置知识
一、前言
在学习爬虫之前,需要我们了解一些前置的知识,包括常用术语,开发流程,抓包工具,前端标签等。
二、常用术语
URL/url: URL 是 Uniform Resource Locator 的缩写,也就是统一资源定位符。它是一种标准化的方式来标识互联网上的资源,如网页、文件、图像等。一个典型的 URL 格式如 https://www.example.com/path/to/page.html,包含了协议(https)、域名(www.example.com)和资源路径(/path/to/page.html)等信息。URL 让用户可以轻易地访问和共享网络上的资源。
简单的介绍就是网址。比如:https://www.baidu.com/
API:API 是 Application Programming Interface 的缩写,指的是应用程序之间交互和通信的一种接口。API 允许不同的软件系统相互连接和交换数据。开发者可以利用 API 来创建集成不同应用的新功能和服务。常见的 API 类型有 REST API、SOAP API 等。
简单来说,就是数据包传递过程中,需要使用到的url地址。
比如:https://api.bilibili.com/x/polymer/web-dynamic/v1/feed/nav?update_baseline=935726292670611537,当你打开这个url地址就可以发现,里面存在着我们可能需要的数据。
抓包:抓包是一种网络监控和诊断技术,用于捕获和分析在计算机网络上传输的数据包。它可以帮助开发者或系统管理员了解网络流量、诊断网络问题、监测安全问题等。常见的抓包工具有 Wireshark、tcpdump 等。
简而言之,抓包就是找到网址传输数据时传输的数据包。
抓包工具:就是用于抓取数据包的工具。
三、爬虫开发基本流程
近几年随着大家互联网冲浪的需求不断攀升,传统的那种后端渲染前端页面的方式已经满足不了快速迭代变化的需求了,所以基于前后端分离的应用越来越多. 大多数我们写的爬虫代码的目标站点都是这种前后端分离的应用,我建议大家可以去网上稍微瞄一下前后端分离的一些技术实现,看个大概就行,对这个前后端分离的这种应用有一些理解,在你后续写爬虫有一些帮助。
现代的网络爬虫工作流程大致可以分为以下几个步骤:
- 识别入口点:确定需要抓取数据的API入口点。这些入口点是爬虫开始抓取数据的起点,通常是一些返回JSON数据的URL。
- 构造请求:根据API文档或通过分析网络请求,构造出正确的HTTP/HTTPS请求。这包括正确的请求方法(GET、POST等)、请求头、以及必要的参数。
- 发送请求:爬虫对API入口点发起请求,等待服务器响应。对于需要认证的API,可能还需要处理登录和会话管理。
- 解析响应:服务器返回JSON或其他格式的数据。爬虫需要解析这些数据,提取有价值的信息。
- 数据处理:将提取出的数据进行清洗、转换和存储。数据可以存储在数据库、文件或其他存储系统中。
- 遍历与递归:从返回的数据中提取出新的URL或API入口点,重复上述过程,直至抓取到所需的全部数据。
关键技术点
HTTP/HTTPS协议
不知道http和https协议的可以看下MDN WEB对于HTTP的讲解 理解HTTP和HTTPS协议是开发网络爬虫的基础。这些协议定义了客户端和服务器之间如何交换数据。
请求库
- Requests:Python的Requests库是处理HTTP请求的同步库,简单易用,适合初学者。
- Aiohttp:Aiohttp是一个支持异步请求的库,可以在处理大量并发连接时提高效率。
- HTTPX:HTTPX支持同步和异步请求,是一个现代化的网络请求库,提供了丰富的功能。
解析库
自从我用了Parsel之后,我解析网页的库再也没用过其他的了,可以基于css选择器,也可以基于xpath,是从Scrapy框架中的解析库做了二次封装得来的,所以我把它推荐给你、
- Parsel:Parsel基于lxml,专为HTML/XML解析设计,简化了数据提取的流程。
浏览器自动化测试工具
优先推荐Playwright,因为现在Python的异步编程很流行,那基于异步的爬虫代码也很多,Playwright它也是支持异步调用, 并且微软开源的,更新迭代速度还行,这也是我推荐的。
- Playwright:Playwright是一个由Microsoft开发的现代化浏览器自动化库。它支持所有主流浏览器和多种语言,特别适合高效率的自动化测试和爬虫开发。
- Selenium:Selenium是一个浏览器自动化工具,可以模拟用户操作浏览器。它支持多种编程语言和浏览器,适合处理JavaScript渲染的页面。
- DrissionPage:是一个基于 Selenium 的 Web 自动化测试框架。它提供了一个面向对象的 API,可以帮助开发者更容易地编写 Web 自动化测试脚本。
四、抓包工具
利用各种工具抓包网络请求
在进行网络爬虫开发时,抓包是一个非常重要的步骤。它可以帮助我们了解客户端和服务器之间的通信过程,包括请求的发送和响应的接收。这对于分析和模拟网络请求尤其关键。本教程将介绍几种常用的抓包工具,包括Chrome的开发者工具、Charles和Fiddler。
- Chrome抓包Web应用
- Charles和Fiddler既可以抓包APP也可以抓包Web
使用Chrome的开发者工具
我之前写了一篇博客微博爬虫的示例,其中有关于Chrome F12抓包的文章,感兴趣的可以去看下:微博帖子评论爬取教程
Chrome浏览器内置的开发者工具是最直接便捷的抓包方式之一,特别适合前后端分离的网站分析。
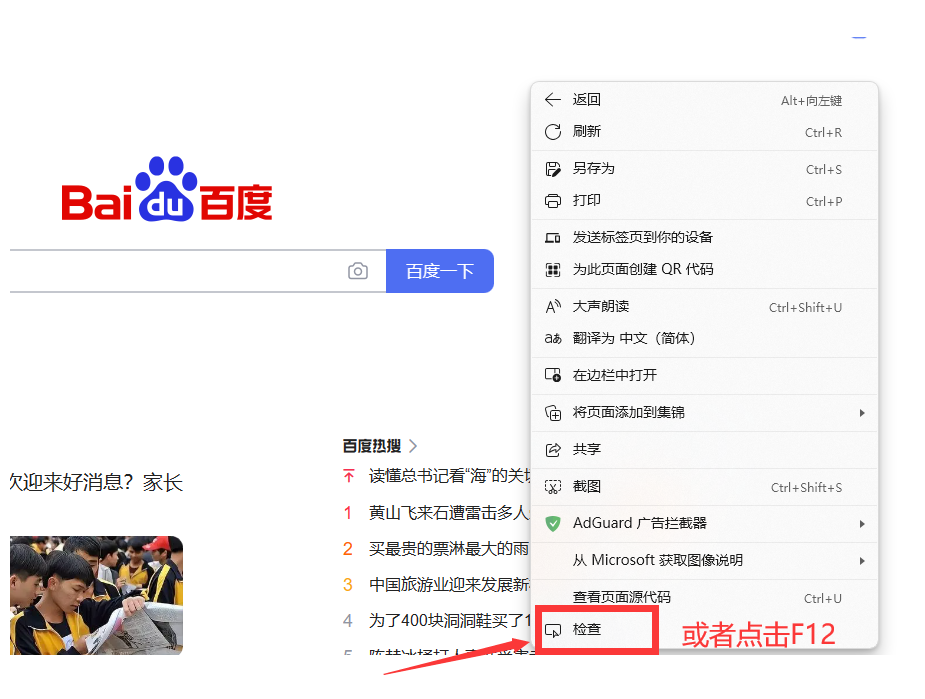
打开Chrome浏览器,访问目标网站。
按
F12或右键点击页面,选择“检查”打开开发者工具。切换到“Network”(网络)标签页。此时可能需要刷新页面以捕获所有网络请求。
浏览网络请求列表,点击任一请求查看详细信息,包括请求头、响应头、响应体等。
可以通过过滤器筛选特定类型的请求,例如XHR(Ajax请求)。
使用Chrome开发者工具的优点在于无需安装额外软件,操作简单,适合快速查看和分析HTTP/HTTPS请求。
然后刷新页面,重新加载网站,让服务端重新发送数据给我们。
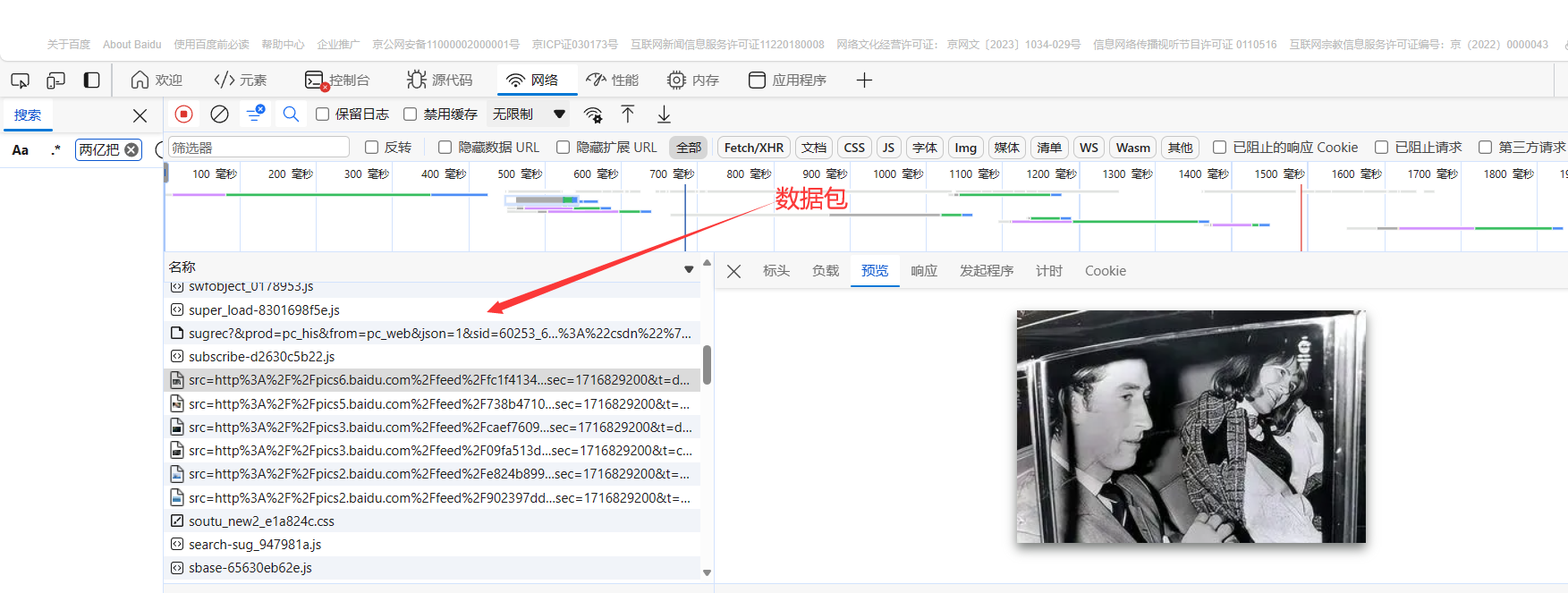
使用Charles
当我有抓取APP或者小程序等需求的时候,我用charles比较多一些,因为它对Macos支持比较友好。 具体安装和使用示例可以看这篇文章,写的比较细:charles安装入门使用示例
Charles是一款广受欢迎的跨平台抓包工具,它可以作为代理服务器运行,监控和修改进出电脑的所有HTTP和HTTPS请求。
- 下载并安装Charles。
- 启动Charles,它会自动开始捕获网络请求。
- 配置浏览器或设备使用Charles为代理服务器。这通常涉及到设置代理服务器地址为127.0.0.1(本机地址),端口为Charles显示的端口(默认8888)。
- 访问目标网站或应用,Charles会显示通过它的所有请求和响应。
- 双击任一请求或响应以查看详细内容。
Charles强大之处在于它能够修改请求或响应,实现更深入的测试和分析。
使用Fiddler
这款工具在windows平台很火,我之前在上一家公式做一些爬虫的小需求有用过,整体尚可,但是好像已经开始收费了,免费版的功能又受限。 具体安装和使用示例可以看这篇文章,写的比较细:Fiddler安装入门使用示例
Fiddler同样是一款功能强大的网络请求分析工具,它也可以捕获计算机上的HTTP/HTTPS请求。
- 下载并安装Fiddler。
- 启动Fiddler,它默认开始捕获网络请求。
- 在“Web Sessions”窗口中,可以看到通过Fiddler的所有HTTP/HTTPS请求和响应。
- 点击任一条目查看详细的请求和响应信息。
Fiddler提供了广泛的自定义选项,包括断点设置、请求编辑、性能测试等高级功能。
总结
抓包是网络爬虫开发中不可或缺的一环。通过使用Chrome开发者工具、Charles、Fiddler等工具,我们可以有效地分析和理解客户端与服务器之间的通信过程。这些工具各有特点,选择合适的工具可以大大提高爬虫开发的效率和质量。
五、常见的前端标签认识
前端(页面展示)最基础的三件套HTML,CSS,JavaScript鼓励大家去了解学习一下,此处只讲解可能遇到的最常见的标签。
下面给出的示例可以创建一个html文件,然后在浏览器打开它,使用F12开发者工具分析。
- 基础标签示例:
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<h1>Welcome to my website!</h1>
</body>
</html>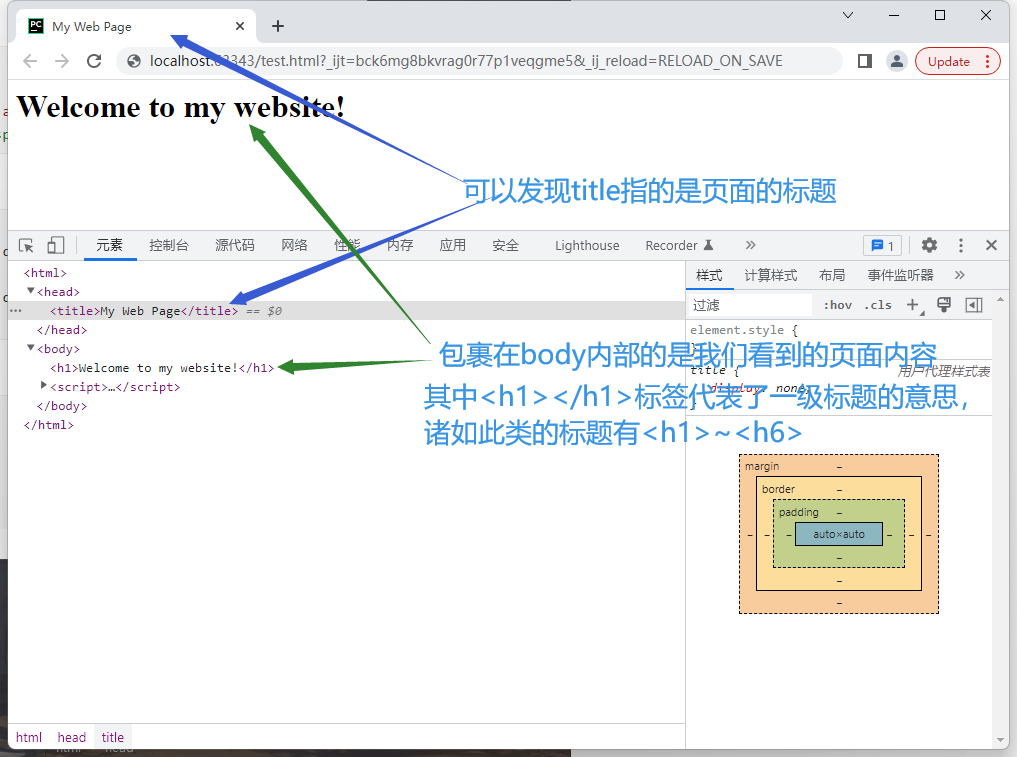
2.文本标签示例:
<h1>This is a Heading 1</h1>
<p>This is a paragraph of text.</p>
<a href="https://www.example.com" target="_blank">Click me</a>
<span style="color:red;">This text is red.</span>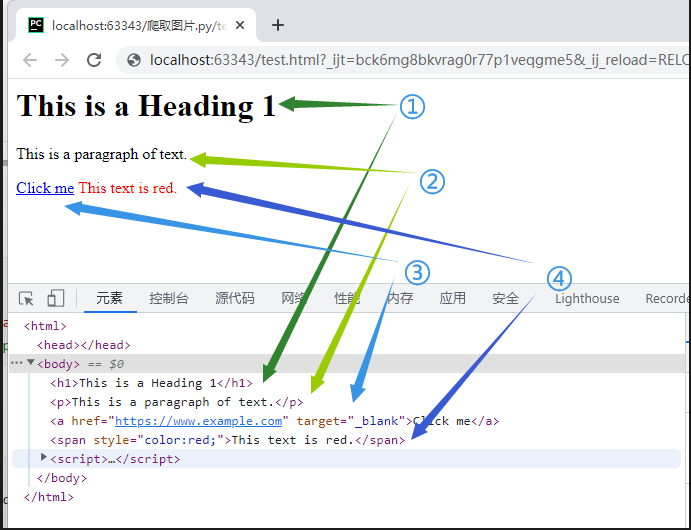
①:<h..>此类标签表示 ..级标题的含义,比如<h2>内容</h2>表示”内容“将以二级标题的方式进行展示。
②:<p>内容</p>:p标签表示被包裹的”内容“将以段落的形式展示。
③:<a>```</a> :定义超链接。href 属性指定链接地址,target 属性指定打开方式。当点击a标签时,就会跳转到href指向的地址。
④:<span> 用于对文本进行样式设置,通常与 CSS 配合使用。作用与p标签类似,但是可以在style属性里面添加样式,比如例子中的 color=red,就将内容渲染成了红色。
3.图像和多媒体标签示例:
<img src="image.jpg" alt="My Image">
<video src="video.mp4" controls>Your browser does not support the video tag.</video>
<audio src="audio.mp3" controls>Your browser does not support the audio tag.</audio>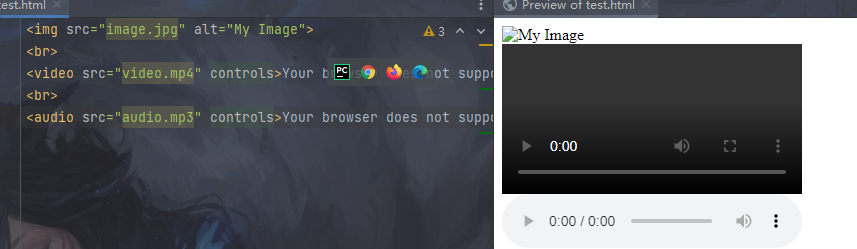
<img>: 插入图像。src属性指定图像文件路径,alt属性提供图像的替代文字描述(当图片无法正常渲染展示时使用)。<video>和<audio>: 插入视频和音频文件。src属性指定媒体文件路径,controls属性显示播放控件。
4.列表标签示例:
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<ol>
<li>First</li>
<li>Second</li>
<li>Third</li>
</ol>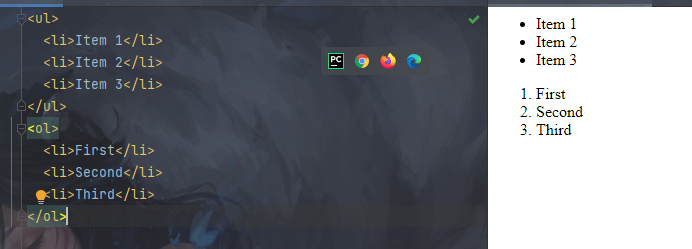
<ul> 和 <ol>: 分别定义无序和有序列表。<li> 定义列表项。
5.表单标签示例:
<form>
<label for="name">Name:</label>
<input type="text" id="name" name="name"><br>
<label for="email">Email:</label>
<input type="email" id="email" name="email"><br>
<button type="submit">Submit</button>
</form>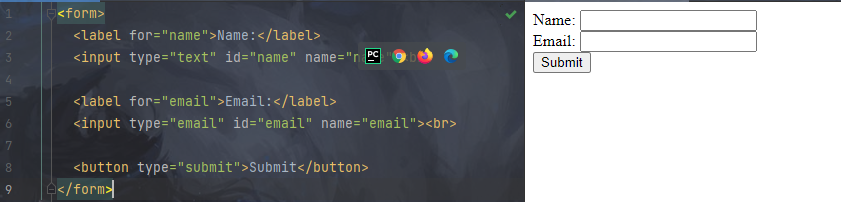
<form>: 定义表单。<input>定义输入字段,type属性指定字段类型,name属性指定字段名称,value属性指定默认值。<label>为<input>元素定义标签。<button>定义提交按钮。
6.布局标签示例:
<header>
<nav>
<ul>
<li><a href="#">Home</a></li>
<li><a href="#">About</a></li>
<li><a href="#">Contact</a></li>
</ul>
</nav>
</header>
<main>
<div>
<h2>Main Content</h2>
<p>This is the main content of the page.</p>
</div>
<aside>
<h3>Sidebar</h3>
<p>This is the sidebar content.</p>
</aside>
</main>
<footer>
<p>© 2024 My Website</p>
</footer><div>: 定义文档中的分区或节,通常用于布局和样式设置。<header>,<nav>,<main>,<aside>,<footer>: HTML5 新增的语义化布局标签,更好地描述页面结构。
这些示例展示了 HTML 标签的基本用法和属性。在爬虫实际开发中,只需要认识这些标签,以及相应的属性作用即可,当然也推荐大家去学习相关知识,尤其是JavaScript。
四、结语
有任何问题欢迎大家的评论和指正。再次声明,本专栏只做技术探讨,严谨商用,恶意攻击等。
这是我的 GitHub 主页:Rosyrain (github.com),里面有一些我学习时候的笔记或者代码。
欢迎大家Follow/Star/Fork三连。
参考文献来源:NanmiCoder/CrawlerTutorial: 爬虫入门、爬虫进阶、高级爬虫 (github.com)