
多进程、多线程、异步协程
本文从操作系统层面讲解 Python 中的多进程、多线程和异步协程是如何提高代码运行效率以及相关概念及其应用场景。多进程适用于 CPU 密集型任务,多线程适合 IO 密集型任务,而异步协程则在超高并发 IO 场景下表现出色。文章通过生动的比喻和代码示例,详细解释了它们的优缺点及使用场景,并提供了规范的代码示例和爬虫实战案例。最后强调,选择合适的工具是高效多任务编程的关键。
Python中的多进程、多线程与异步协程:从操作系统到代码效率的奇妙冒险
1.计算机世界的"心脏手术":CPU如何同时处理多个任务
在计算机的世界里,CPU(中央处理单元)是处理任务的核心设备。就像云服务商常用的2c2g配置:
2c表示2个CPU核心(相当于两位厨师)2g表示2GB内存(相当于两个备菜台)
原理:
- 内存主要用于临时存储运行中的程序数据
- 每个CPU核心在同一时刻只能处理一个任务(多进程,多线程引入的原因)
- 现代操作系统通过时间分片技术实现多任务处理
生动案例: 想象你是一位单核CPU厨师(只有一双手),却要同时处理:
- 煎牛排(任务A)
- 煮意面(任务B)
- 烤蛋糕(任务C)
聪明的餐厅经理(操作系统)发明了时间分片法:
[煎牛排10ms] -> [煮意面10ms] -> [烤蛋糕10ms] -> 循环...虽然每道菜都是"断断续续"地做,但由于切换速度极快(人类感知约0.1秒),顾客感觉三道菜是"同时"在做。这就是现代操作系统的魔法——宏观并行,微观串行。
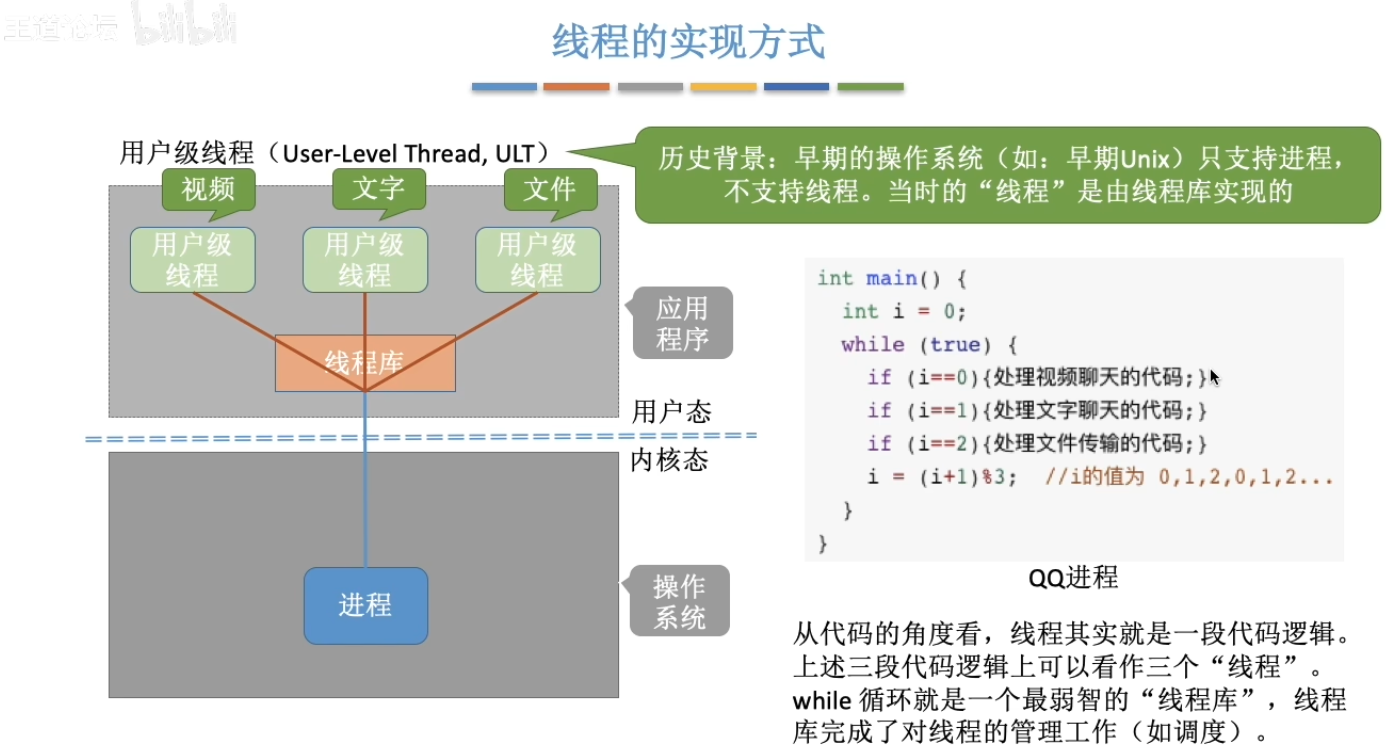
技术细节:
- 单核CPU通过快速任务切换(每秒数百次)模拟"并行"
- 多核CPU(如2c配置)才能实现真正的并行处理
- 任务数量通常远多于CPU核心数,所以仍需分时调度
趣味知识:早期的单核CPU就像"闪电侠",靠极速切换制造"分身术"假象;而现代多核CPU则是真正的"复仇者联盟",每个核心都能独立作战。
关键结论:
- 单核CPU的"并行"本质上是快速串行切换(宏观并行,微观串行)
- 多核CPU可以真正并行执行任务(每个核心处理不同任务)
- 操作系统调度程序就像米其林餐厅经理,精心安排每个"厨师"的工作流程
这种设计既解释了为什么老式单核电脑也能"同时"运行多个程序,也说明了为什么多核CPU能显著提升性能——就像从单人厨房升级为专业厨师团队!
小知识:云服务器的"2c2g"配置就像请了两位厨师(2核CPU)和两个备菜台(2GB内存)。厨师越多,能真正同时做的菜就越多!
2. 进程与线程:餐厅里的组织架构
2.1 进程:独立承包的厨房
每个进程就像餐厅里独立承包的厨房:
- 有自己的厨具(内存空间)
- 自己的食谱(程序代码)
- 自己的储物柜(系统资源)
- 崩溃了不会影响其他厨房(稳定性高)
但开新厨房成本很高(创建进程开销大),而且厨房之间传菜要通过特殊通道(IPC通信)
# Python创建新进程
import os
print(f"主厨PID:{os.getpid()}正在备餐")
pid = os.fork() # 开新厨房!
if pid == 0:
print(f"学徒PID:{os.getpid()}在做甜点")
else:
print(f"主厨PID:{os.getpid()}在做主菜")2.2 线程:厨房里的帮厨团队
线程则是同一个厨房里的帮厨:
- 共享所有厨具(内存空间)
- 共用同一个食谱(程序代码)
- 传菜直接递过去就行(通信简单)
- 但万一有人打翻面粉...整个厨房遭殃(线程崩溃影响整个进程)
# Python创建线程
import threading
def 做披萨():
print(f"{threading.current_thread().name}正在甩面饼")
def 煮咖啡():
print(f"{threading.current_thread().name}正在磨咖啡豆")
# 两个帮厨开始工作
threading.Thread(target=做披萨).start()
threading.Thread(target=煮咖啡).start()生活案例:Chrome浏览器每个标签页是独立进程(崩溃不互相影响),而Word的多线程让你可以边打字边检查拼写。
3. Python的多任务三剑客
3.1 多进程:开连锁店
适合场景:
- CPU密集型任务(比如做满汉全席)
- 需要稳定性(一个分店着火不影响总部)
from multiprocessing import Process
import os
def 分店任务(分店名):
print(f"{分店名}(PID:{os.getpid()})开张啦!")
if __name__ == '__main__':
分店列表 = []
for i in range(3):
p = Process(target=分店任务, args=(f"分店{i}",))
p.start()
分店列表.append(p)
for p in 分店列表:
p.join() # 等待所有分店打烊进程池版(管理多家分店更轻松):
from multiprocessing import Pool
def 处理订单(订单号):
return f"订单{订单号}已完成"
with Pool(4) as pool: # 4个分店同时接单
results = pool.map(处理订单, range(10))
print(results)3.2 多线程:雇佣更多服务员
适合场景:
- IO密集型任务(比如等外卖小哥送食材)
- 需要快速响应(服务员随叫随到)
import threading
import time
def 接电话(客户名):
time.sleep(1) # 模拟等待时间
print(f"{threading.current_thread().name}服务{客户名}")
客户列表 = ["Alice", "Bob", "Charlie"]
for 客户 in 客户列表:
threading.Thread(target=接电话, args=(客户,)).start()线程池版(避免无限招人):
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=3) as executor:
executor.map(接电话, 客户列表)3.3 异步协程:全能型服务员
协程就像会分身术的服务员:
- 遇到等待(比如等水烧开)就去做别的事
- 单线程就能处理大量IO任务
- 但需要特殊训练(async/await语法)
import asyncio
async def 煮面():
print("开始烧水...")
await asyncio.sleep(2) # 假装在等水开
print("面条下锅啦!")
async def 煎蛋():
print("热油中...")
await asyncio.sleep(1)
print("鸡蛋煎好了!")
async def 主厨():
await asyncio.gather(煮面(), 煎蛋()) # 同时盯两件事
asyncio.run(主厨())有趣事实:协程的切换成本比线程低100倍!就像服务员转身比雇新人快得多。
4. 终极对决:何时用谁?
| 维度 | 多进程 | 多线程 | 异步协程 |
|---|---|---|---|
| 适用场景 | CPU密集型(计算圆周率) | IO密集型(网络请求) | 超高并发IO(百万连接) |
| 创建开销 | 大(开新餐厅) | 小(雇新员工) | 极小(分身术) |
| 通信成本 | 高(得用对讲机) | 低(直接喊话) | 极低(心电感应) |
| 崩溃影响 | 只影响自己(防火门) | 全店遭殃(开放式厨房) | 整个事件循环崩溃 |
| Python限制 | 不受GIL限制 | 受GIL限制(只有一个厨师证) | 完全避开GIL |
黄金选择法则:
- 计算密集型:多进程(如数据分析)
- IO密集型:多线程或协程(如爬虫)
- 超高性能需求:协程(如Web服务器)
- 不确定时:
ProcessPoolExecutor+ThreadPoolExecutor混合双打!
5. 避坑指南:多任务中的"厨房事故"
5.1 死锁:两个厨师互相等调料
# 错误示范!
lock1 = threading.Lock()
lock2 = threading.Lock()
def 厨师A():
with lock1:
with lock2: # 卡在这里等lock2
print("厨师A完成")
def 厨师B():
with lock2:
with lock1: # 卡在这里等lock1
print("厨师B完成")解决方案:按固定顺序获取锁,或者使用with语句。
5.2 GIL:Python的"独家厨师证"
Python有个叫GIL(全局解释器锁)的机制,就像全店只有一张厨师证,导致多线程在CPU密集型任务时反而变慢。
绕过方法:
- 用多进程(每个进程有自己的GIL)
- 用C扩展(如NumPy)
- 换解释器(如PyPy)
5.3 协程忘记await
async def 煮汤():
print("开始煮汤")
asyncio.sleep(3) # 错误!忘记await
print("汤煮好了") # 会立即执行正确做法:所有异步操作前加await。
6.规范示例
6.1 多进程示例(ProcessPoolExecutor)
import concurrent.futures
import multiprocessing
import os
import time
def task(name):
print(f"Process {os.getpid()} executing {name}")
time.sleep(1) # 模拟CPU密集型任务
return f"Result of {name}"
def main():
# 根据CPU核心数自动设置worker数量
workers = min(multiprocessing.cpu_count(), 4)
with concurrent.futures.ProcessPoolExecutor(max_workers=workers) as executor:
futures = [executor.submit(task, f"Task-{i}") for i in range(5)]
for future in concurrent.futures.as_completed(futures):
try:
result = future.result()
print(result)
except Exception as e:
print(f"Error occurred: {e}")
if __name__ == "__main__":
main()6.2 多线程示例(ThreadPoolExecutor)
import concurrent.futures
import threading
import time
def task(name):
print(f"Thread {threading.current_thread().name} executing {name}")
time.sleep(1) # 模拟IO密集型任务
return f"Result of {name}"
def main():
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, f"Task-{i}") for i in range(5)]
for future in concurrent.futures.as_completed(futures):
try:
result = future.result()
print(result)
except Exception as e:
print(f"Error occurred: {e}")
if __name__ == "__main__":
main()6.3 异步协程示例(asyncio)
import asyncio
import time
async def task(name):
print(f"Coroutine executing {name}")
await asyncio.sleep(1) # 模拟异步IO操作
return f"Result of {name}"
async def main():
tasks = [task(f"Task-{i}") for i in range(5)]
try:
results = await asyncio.gather(*tasks)
for result in results:
print(result)
except Exception as e:
print(f"Error occurred: {e}")
if __name__ == "__main__":
# Python 3.7+ 的推荐运行方式
asyncio.run(main())异步协程中常用到的还有 aiohttp(用于异步发送网络请求),aioflies(异步打开文件)
增强版异步协程示例:爬取某网站的小说(aiohttp + aiofiles)
import asyncio
import aiohttp
import aiofiles
import os
from lxml import etree
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0"
}
async def parse_home():
home_url = "https://www.zibq.cc/html/6995/"
async with aiohttp.ClientSession() as session:
async with session.get(home_url, headers=headers) as resp:
html = await resp.text()
home_html = etree.HTML(html)
div = home_html.xpath('//div[@class="listmain"]')[0]
chapter_links = div.xpath('.//a/@href')
title = home_html.xpath('//h1/text()')[0]
return title, chapter_links
async def parse_chapter(title, url, session,semaphore):
async with semaphore:
chapter_url = 'https://www.zibq.cc' + url
count = url.split('/')[-1].replace('.html', '')
print(f"正在爬取chapter_url:{chapter_url}")
if not chapter_url.startswith('http') or not chapter_url.endswith('html'):
return
async with session.get(chapter_url, headers=headers) as resp:
if resp.status != 200:
print(f"请求失败chapter_url: {chapter_url}")
return
text = await resp.text()
html = etree.HTML(text)
chapter_title = html.xpath('//h1/text()')[0]
p_list = html.xpath('//div[@id="chaptercontent"]//text()')
content = '\n'.join(p_list[:-4])
content = content.replace(r'\u3000', ' ')
file_title = f"{count}_{chapter_title}"
await save_chapter(title, file_title, content)
print(f"保存成功chapter_title:{chapter_title}")
async def save_chapter(title, chapter_title, content):
# 确保文件名合法
chapter_title = ''.join(c for c in chapter_title if c.isalnum() or c in (' ', '_'))
async with aiofiles.open(f'./{title}/{chapter_title}.txt', 'w') as f:
await f.write(content)
async def main():
title, chapter_links = await parse_home()
print(title, chapter_links)
if not os.path.exists(title):
print(f"创建文件夹{title}")
os.mkdir(title)
# 添加并发限制
semaphore = asyncio.Semaphore(10) # 最大并发数为10
async with aiohttp.ClientSession() as session:
tasks = [
asyncio.ensure_future(parse_chapter(title, url, session,semaphore)) for url in chapter_links
]
await asyncio.gather(*tasks)
if __name__ == '__main__':
# asyncio.run(main())
asyncio.get_event_loop().run_until_complete(main())关键组件说明
aiohttp:
- 异步HTTP客户端/服务器
- 使用
ClientSession管理连接池 - 支持超时设置 (
ClientTimeout) - 典型性能:单线程可处理数千并发连接
aiofiles:
- 提供异步文件IO
- API设计与标准文件操作相似
- 避免阻塞事件循环
注意事项
错误处理:
- 网络请求必须设置超时
- 文件操作需要处理权限问题
- 使用
gather的return_exceptions=True可防止单个任务失败影响整体
资源限制:
# 限制并发量 semaphore = asyncio.Semaphore(10) async with semaphore: await fetch_url(session, url)生态整合:
- 数据库:
asyncpg(PostgreSQL),aiomysql - 消息队列:
aio-pika(RabbitMQ) - Web框架:
FastAPI,aiohttp.web
- 数据库:
这个示例展示了异步编程在IO密集型场景下的强大能力,通过结合现代异步生态库,可以轻松实现高性能应用。
7. 结语:没有银弹,只有合适的工具
"没有银弹"(No Silver Bullet)是软件工程领域的经典概念,源自IBM科学家弗雷德里克·布鲁克斯1986年的论文。它用狼人传说中"银质子弹能杀死怪物"的比喻,说明软件开发不存在能一次性解决所有问题的"终极解决方案"
该概念最初针对软件开发,但已延伸至项目管理、技术创新等领域,成为应对复杂系统的通用思维模型,就像现实中不存在能杀死所有怪物的银弹,复杂问题往往需要综合施策
就像米其林餐厅需要:
- 主厨(主进程)
- 帮厨(线程)
- 外卖协调员(协程)
- 分店(多进程)
你的Python程序也需要根据任务特点选择合适的多任务方式。记住:
- 多进程是"不同办公室"
- 多线程是"同一办公室的同事"
- 协程是"会分身的超人"
最后送大家一句Python多任务编程的"心法":
"不要用共享内存来通信,要用通信来共享内存" —— Go语言名言(同样适用于Python)
总结
“没有银弹”,Python多任务编程没有一劳永逸的解决方案。就像经营餐厅需要合理安排主厨、帮厨、外卖员一样,你需要根据任务特点选择合适的工具。记住:“不要用共享内存来通信,要用通信来共享内存”,这是高效多任务编程的关键心法。 总之,无论是CPU、进程、线程还是协程,都是Python多任务编程的“厨房秘籍”。只有根据任务需求灵活运用,才能让程序运行得又快又好。